Neglect of variation, analysis of variance
Please note: I was not involved in this experiment. I am recounting the events of the experiment as well as I observed them from the outside. Some of the details have been simplified to ease reporting on them in my blog.
There was an experiment conducted at my employer about six years ago. The goal of the experiment was to select a material resistant to cavitation erosion. The material was to go into a piping system where it would be subjected to severe cavitation.
There was a sample tested for each candidate material. The testing entailed putting the sample under thermo-hydraulic conditions replicating those in the actual flow loop. After exposure to the test conditions the number of cavitation pits in the sample was counted. The data resembled something like that in graph below.
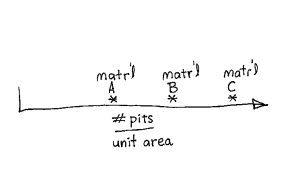 There were three materials tested. There was a count of cavitation pits per unit area for each material. The best material for the application is material A, right? What could be simpler than that?
There were three materials tested. There was a count of cavitation pits per unit area for each material. The best material for the application is material A, right? What could be simpler than that?
In selecting material A there is actually a hidden unstated assumption. The assumption is that there is little to no variation in the material properties. If you were to rerun the test with additional samples you would get essentially the same result. To word it another way there is a low coefficient of variation. . If this assumption is true and we run the test multiple times and we then plot the data from these tests as a probability distribution we would have something that would look like what is shown below, the data from the original actual test is indicated with the asterisk.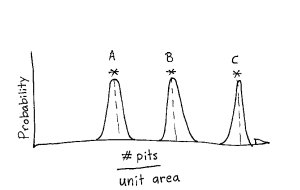
But the sad, ugly reality is that we cannot make that assumption without additional information. Material testing can have wide scatter in the data. Samples of nominally identical material but from different lots can have widely varying properties.
For all we know the probability distribution from running multiple samples would look like this:
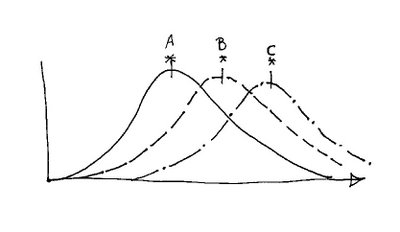
Once again the actual data from the original test is shown with an asterisk. In this case there is no longer a significant difference in the behavior of the three materials. I am assuming that our one datapoint for each material falls at the mean. But based on the experimental data we can’t even be sure of that.
For all we know the distributions look like this:
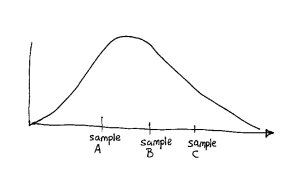
In this case there is no difference in the three materials. All we have is three datapoints from a single distribution curve.
Worse yet, perhaps the true, unknown, distributions look like what is shown below here.
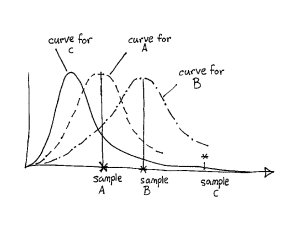
The one datapoint for C which did worse than our one datapoint for A and one datapoint for B is actually drawn from a distribution whose mean is better than that of A and B.
Based on the limited amount of data and no information as to what the distributions are there is no reliable way to select between materials A, B, or C.
The way to conduct a test such as this and make a reliable determination is to run multiples of each sample so we can distinguish the variation within a sample material and between sample materials. The statistical procedure to use is called analysis of variance or ANOVA.
tags:
Mechanical Engineering
Analysis of variance
ANOVA
posted by JBC at 4:03 PM
![]()
![]()

2 Comments:
You are to be commended, sir, for a statistics lessen we can understand. And you did it without any jargon, equations, or autocad! I appreciate you blog. Good luck with everything.
Thank you for your appreciation. I will be posting some more on this topic.
JB Chesser
Post a Comment
<< Home